Yesterday’s post continued the theme of the lack of understanding of validity in both the design of tests at all levels and interpretation of their scores. In service of that argument, I quoted from a chapter by Emily Shaw in the book Measuring Success edited by Jack Buckley, Lynn Letukas, and Ben Wildavsky: “Decades of research has shown that the SAT and ACT are predictive of important college outcomes, including grade point average (GPA) [in college], retention, and completion, and they provide unique and additional information in the prediction of college outcomes over high school grades. (Emphasis added) This statement occurs within a chapter of the book where Shaw “recounts numerous studies that unfailingly conclude that admissions tests are strong and reliable predictors of college performance that become even stronger when coupled with high school grade point average (HSGPA).
Far too many to link here dispute this finding. Just yesterday, in browsing for some material about validity I came across someone who said with great authority that since less than 20% of college performance could be predicted by SAT that it was a useless exam. In that statement like those of many other understandably frustrated folks, there is a palpable misapprehension regarding predictive validity, a specific interpretation of the scores from a test in such a way as to predict a future outcome such as performance in a course of study or job. To put the term more crassly, predictive validity can be thought of as telling you what’s the best bet upon which to place your money in a course of action. And, as that noted amateur statistician, Damon Runyon, once stated regarding a racecourse and its associated action , “The race is not always to the swift, nor the battle to the strong—but that’s the way to bet!” Predictive validity is supposed to tell you who is likely to be the swiftest, the strongest, the smartest, the sanest depending upon the particular construct being investigated.
But predictive validity is misunderstood in part because its numbers are viewed by those not in the priesthood of psychometrics as being less substantial than they actually are. In this fairly technical paper, one of the most brilliant explicators of assessment, Howard Wainer, and his co-author Daniel H. Robinson highlight the large importance of small numbers when it comes to predictive validity. They used an example that most adults — at least those over 40 – would understand and that as Bridgeman, Burton, and Cline put it in their own paper “clearly showed the potential value of experimental treatments that explain only a miniscule percentage of the variance in the outcome variable. Wainer and Robinson (2003) cited data from a large-scale study in which 22,071 physicians were randomly assigned to take either aspirin or a placebo every other day over a five-year period and the outcome variable was a heart attack. Using a traditional explained variance approach indicated that much less than 1% of the variance in getting a heart attack could be explained by taking (or not taking) aspirin. (The r 2is .001.) Focusing instead on the number of people in each group who actually had heart attacks told a far different story. In the group taking the aspirin, 104 participants had heart attacks; in the placebo group, there were 189, or almost twice as many.” Small number with a big impact. As Wainer and Robinson comment about the aspirin study: “In this case, at least 85 physicians (i.e., the ones who did not get heart attacks) would testify to the practical significance of an effect whose r 2 is zero to two decimal places.”
The same ‘ practical significance of an effect‘ can be true of predictive validity when it comes to education; here are Brent, Nancy, and Fred again. (I knew them all at ETS and thus feel okay using first names. If you haven’t figured out by now that this is not an academic journal’s webpage than you just haven’t been paying attention. And my use of GRE does not suggest that I think that this is a perfect assessment; in later posts, I will argue that it could and should be both different and better.)
“Without a correction for restriction in range used in the above studies, the correlation of GRE scores and first-year graduate grades is about 0.3, explaining about 9% of the variance. To test critics, this appears to be a trivially small number. “The ability of the GRE to predict first-year graduate grades is incredibly weak, according to data from the test’s manufacturer. In one ETS study of 12,000 test takers, the exam accounted for a mere (emphasis added) 9% of the differences (or variation) among students’ first-year grades” (The National Center for Fair and Open Testing [FairTest], 2001). Methods of describing the value of the GRE that do not rely on “explained variance” would be more comprehensible to the various audiences that evaluate the utility of a prediction measure.
I had hoped to provide a link to this article on the ETS website, but somewhere along the way the site underwent reorganization and broke all of its previous links. In fact, I’m not even sure if the audit is even up there anymore. But you can find the article on the good old ERIC website, a place that got me through graduate school thirty years ago, at this link.
So what’s the problem with predictive validity?
Uncertainty and innumeracy
During the last two years, the errors in communication concerning the covert pandemic are legion and they have many different sources. But two of them relate to the situation we are describing here today: uncertainty and innumeracy: the British Medical Journal a few years ago made the point that, “The need to appropriately convey uncertainty—in infectious disease models and more generally—has been emphasised by statisticians for decades.” But the amplification feature of the Internet tends to drown out such caveats and cautions regarding how to interpret any numbers that predict a correlation between two factors; e.g., wearing a mask, getting vaccinated, closing down bars, etc.. Additionally, people are uncomfortable with uncertainty. They would like to live in a world where prediction was more successful. As the Bridgeman Trio note this is not confined to so-called laypersons:
“Since at least 1982, there have been clear warnings that even trained social scientists may be severely underestimating the practical importance of apparently small amounts of explained 2 variance (Rosenthal & Rubin, 1982).”
But our general unfamiliarity with statistics does explain some of the issues faced. Predictive validity is expressed in what are called Correlation Coefficients; figures used in statistics to measure how strong a relationship is between two variables such as your score performance on a test while a senior in high school and the number of years it then takes you to graduate college. As Investopedia has it: “The values range between -1.0 and 1.0. A calculated number greater than 1.0 or less than -1.0 means that there was an error in the correlation measurement. A correlation of -1.0 shows a perfect negative correlation, while a correlation of 1.0 shows a perfect positive correlation. A correlation of 0.0 shows no linear relationship between the movement of the two variables.”
Almost no test – medical, psychological, educational — would ever get that perfect positive correlation of 1.0. Therefore, there’s always going to be uncertainty. And almost no outcome in our world is attributable to a single cause. Each of us is a system living within a system within a system within a system… You get the idea: it’s systems all the way down. And these systems are complex systems: “Complex systems are systems where the collective behavior of their parts entails emergence of properties that can hardly, if not at all, be inferred from properties of the parts. Examples of complex systems include ant-hills, ants themselves, human economies, climate, nervous systems, cells and living things, including human beings, as well as modern energy or telecommunication infrastructures.”
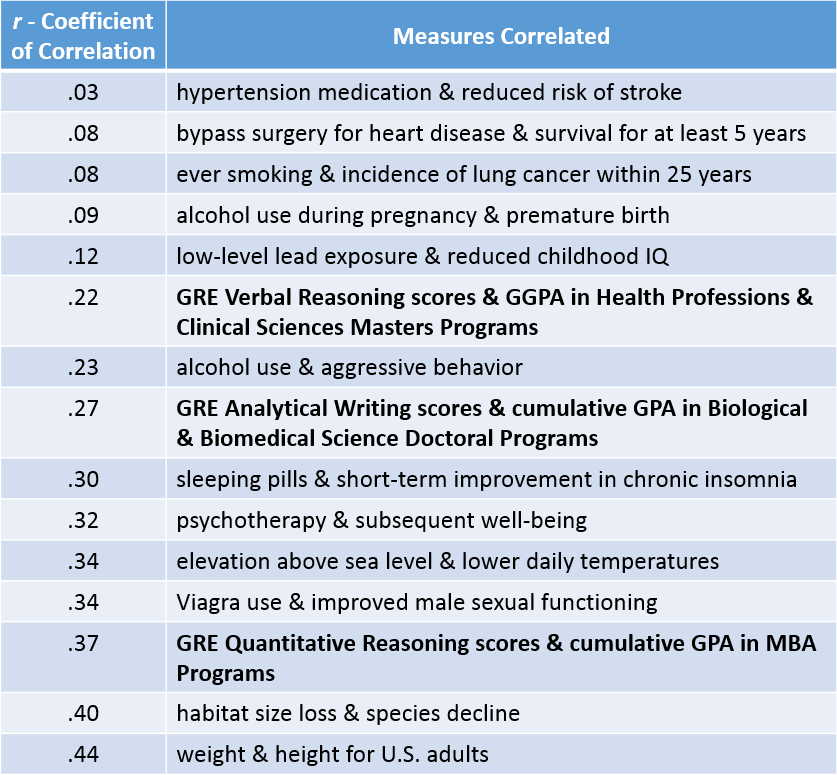
That we can predict even to a small degree how someone will do in the future is miraculous. But to illustrate that in terms of predictive validity, let’s go back to the chart that was at the top of this post and see how GRE® Scores Stack Up:
Each one of the rows in this illustration contains two variables; e.g., hypertension medication and reduced risk of stroke, psychotherapy and subsequent well-being, etc. the number in the column to the left shows the correlation. Brent Bridgeman and another friend and former ETS colleague Harrison Kell spelled out what this means in a different article: “The truth is that the GRE General Test is more highly correlated with graduate-level academic readiness and performance than many commonly accepted correlations curated from popular psychology, medicine and everyday life.” A test takers score on the GRE’s qualitative reasoning section is a better predictor of their GPA in their MBA program than psychotherapy is a predictor of subsequent well-being or Viagra use is a predictor of improved sexual functioning. I select those two examples not just because the Viagra one is irresistible but because there are millions of people in this country who choose one or both of those interventions with the sense that they will work for them. But GRE will work better as a predictor for both the test-taker and the institution in determining the likelihood of success in business school.
It’s not even close. Consider this from from Burton, Cline, and Bridgeman: “Students in the top quartile (of GTE scores) were 3 to 5 times as likely to earn 4.0 averages compared to students in the bottom quartile. Even after controlling for undergraduate grade point average quartiles, substantial differences related to GRE quartile remained.”
Three to five times more likely! The GRE is telling the admissions department a great deal with its scores. The GRE is accurately predicting the likelihood of academic success. There’s a kicker: in one section of the study 13% of students who had been in the lowest quartile of GRE scores subsequently managed to get 4.0 GPAs. The GRE did NOT predict perfectly. Those people likely hate the GRE and so do their mothers and maybe their romantic partners. To them, the GRE appeared to lie, to misrepresent their capabilities. Of course, that’s not the case, but for the purposes of our overall discussion such feelings are important because these individuals are likely to be against tests such as the GRE. And they’re not interested probably in reading this blog either to learn more about predictive validity.
It seems unfair that the scientists do all this work on predictive validity only to have it misunderstood and derided. But we go back to the philosopher Damon Runyon again, we can all agree with his sentiment that “I came to the conclusion long ago that all life is six to five against”. More on predictive validity tomorrow.
If I can take a slightly less technical stance for a moment: This is one area that my students really struggle with, especially the notion that although there might be a strong correlation between two variables (for example, previous test score and amount of time spent revising) and therefore a high likelihood of something happening (scoring well on a test), it is not certain and there are many other possibilities (scoring poorly, or middlingly, or totally acing it), because there are many other variables to take into account: Were they taught the right stuff? Did they revise the right stuff? Did they focus their revision on just the right subset of topics addressed by the test? Was the exam room hot/stuffy/cold/noisy? Did they sleep well the night before the test? Did their favourite/lucky pen run out halfway through the test? Magnify this up across many tests and over many years and you can see how two pupils with pretty much identical assessment profiles at 13 end up in entirely different places academically at 18 and beyond – and that’s not even considering contextual social and economic factors, for example. The numbers scare people, but it can be helpful to humanise them by considering the cumulative effect of small (tiny) differences in terms of inputs and outcomes…
Pingback: The Test-Taker’s Anxiety And The Limits Of Predictive Validity – Testing: A Personal History